Reinforcement Learning (RL) has emerged as a powerful paradigm in artificial intelligence, enabling systems to learn optimal behaviours through trial and error. Unlike supervised learning, where models learn from labelled datasets, RL agents learn by interacting with an environment, receiving feedback as rewards or penalties.
RL-driven systems are transforming industries, from robotics and autonomous vehicles to recommendation systems and industrial automation. However, building such systems requires a deep understanding of RL principles, careful architecture design, and algorithmic choices.
This article explores the foundations of RL, its applications, and best practices for designing and deploying RL-driven systems.
What are RL-Driven Systems?
RL-driven systems are AI-powered solutions where agents learn to make decisions by maximising cumulative rewards. These systems consist of:
-
Agent: The decision-maker that interacts with the environment.
-
Environment: The external system in which the agent operates.
-
Actions: The Moves the agent can take.
-
Rewards: Feedback signals that guide learning.
Unlike traditional rule-based or supervised learning systems, RL agents improve through exploration and exploitation over time, making them ideal for dynamic, complex problems.
Why Use Reinforcement Learning?
RL is beneficial when:
-
No labelled data is available, but a reward mechanism can be defined.
-
The problem involves sequential decision-making (e.g., game playing, robotics).
-
The environment is dynamic, requiring adaptive strategies.
-
Long-term optimisation is needed (e.g., resource allocation, financial trading).
Industries like healthcare (treatment optimisation), logistics (supply chain automation), and gaming (AI opponents) benefit from RL’s ability to learn from interactions.

Foundations of Reinforcement Learning
Reinforcement Learning (RL) is a paradigm where an agent learns to make decisions by interacting with an environment to maximise cumulative rewards. Unlike supervised learning, RL does not rely on labelled datasets but instead learns through trial and error, guided by reward signals.
This section thoroughly explores RL's core concepts and types, providing a solid foundation for building RL-driven systems.
Key Concepts in Reinforcement Learning
Agent & Environment-
Agent: The decision-maker that interacts with the environment. It observes the state, takes actions, and receives rewards.
-
Environment: The external system in which the agent operates. It provides:
-
State (s): A representation of the current situation.
-
Reward (r): Feedback on the agent’s action.
-
Next State (s): The new state after the action.
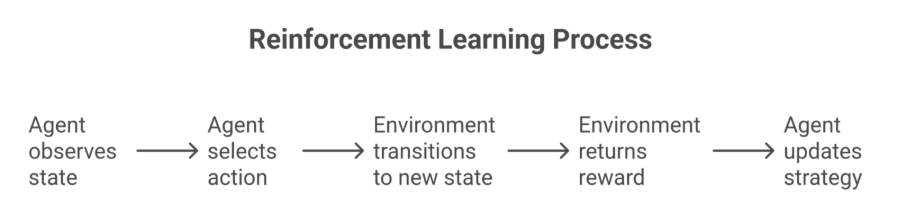
Interaction Flow:
-
Agent observes state (s).
-
Agent selects action (a) based on its policy (π).
-
Environment transitions to a new state (s') and returns a reward (r).
-
The agent updates its strategy based on the reward.
-
A scalar feedback signal indicating how good an action was.
-
Designing rewards is critical: Poorly shaped rewards can lead to unintended behaviours.
-
Credit Assignment Problem: Determining which actions led to rewards in long sequences.
Policy (π)
-
A strategy that maps states to actions.
-
Deterministic Policy: Always takes the same action in a given state (e.g., π(s) = a).
-
Stochastic Policy: Samples actions from a probability distribution (e.g., π(a|s) = P(a|s)).
-
Optimal Policy (π*) maximises long-term rewards.
Value Function (V, Q)
Helps the agent evaluate actions by estimating future rewards.
-
State-Value Function (V(s)): Expected return from state s following policy π.
-
"How good is it to be in this state?"
-
Action-Value Function (Q(s,a)): Expected return from taking action a in state s.
-
"How good is this action in this state?"
-
Bellman Equation: Recursively defines value functions:
V(s)=E[r+γV(s′)]V(s)=E[r+γV(s′)]
(where γ = discount factor, prioritising immediate vs. future rewards.)
Exploration vs. Exploitation-
Exploitation: Choosing the best-known action to maximise rewards.
-
Exploration: Trying new actions to discover better strategies.
Balancing Methods:
-
ε-Greedy: Randomly explores with probability ε, exploits otherwise.
-
Softmax (Boltzmann): Selects actions based on probability weights.
-
Upper Confidence Bound (UCB): Prefers actions with high uncertainty.

Types of Reinforcement Learning
- Model-Free vs. Model-Based RL
|
Aspect |
Model-Free RL |
Model-Based RL |
|
Definition |
Learns directly from experience without modelling the environment. |
Builds a model of the environment to simulate outcomes. |
|
Examples |
Q-Learning, DQN, PPO |
Dyna-Q, Monte Carlo Tree Search (MCTS) |
|
Pros |
Simpler, it works when the environmental dynamics are unknown. |
More sample-efficient, enabling planning. |
|
Cons |
Less efficient, requires many interactions. |
Model inaccuracies can lead to poor decisions. |
-
Q-Learning: Learns a Q-table (state-action values).
-
Deep Q-Network (DQN): Uses neural networks to approximate Q-values for high-dimensional states.
-
Dyna-Q: Combines real experience with simulated rollouts.
-
AlphaZero (Chess/Go): Uses MCTS for planning.
|
Aspect |
On-Policy RL |
Off-Policy RL |
|
Definition |
Learns from actions taken by the current policy. |
Learns from actions not necessarily taken by the current policy. |
|
Examples |
SARSA, REINFORCE |
Q-Learning, DDPG |
|
Pros |
More stable, learns from actual behaviour. |
More flexible, can reuse past data. |
|
Cons |
Less sample-efficient. |
It can be unstable if the policy diverges too much. |
-
On-Policy (SARSA): Updates Q-values based on the following action selected by the current policy.
-
More conservative, follows the policy’s exploration strategy.
-
Off-Policy (Q-Learning): Updates Q-values based on the best possible following action.
-
Can learn from random exploration or human demonstrations.
When to Use Reinforcement Learning
Problem Suitability
RL works best when:
-
Decisions are sequential.
-
Delayed rewards matter.
-
The environment is partially observable.
-
Adaptive behaviour is required.
Use Cases Across Industries
-
Autonomous Vehicles: RL optimises path planning and driving policies.
-
Finance: Algorithmic trading agents maximise returns.
-
Healthcare: Personalised treatment policies improve patient outcomes.
-
Manufacturing: RL optimises supply chains and robotic control.
-
Gaming & AI: Agents learn to play complex games (e.g., AlphaGo).
Architecture of an RL-Driven System
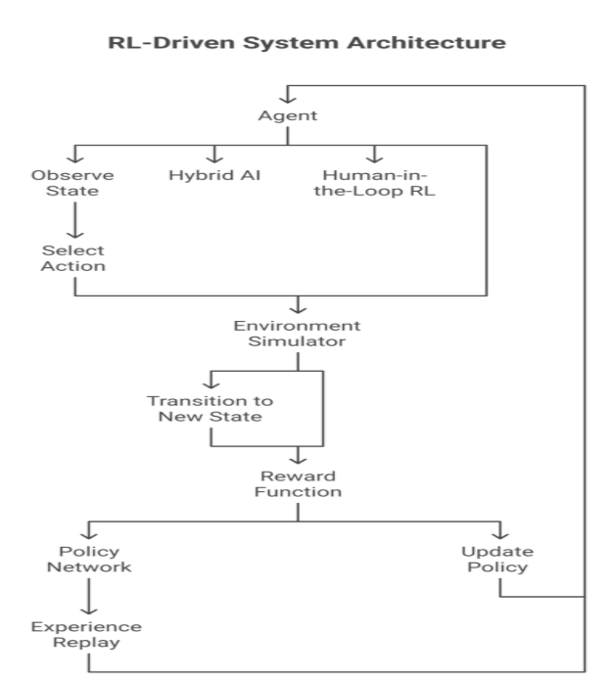
Core Components
-
Agent: Implements the learning algorithm (e.g., DQN, PPO).
-
Environment Simulator: Provides state transitions and rewards (real or simulated).
-
Reward Function: Defines success criteria (must be carefully designed).
-
Policy Network: Neural networks (for Deep RL) or tabular methods (for simple tasks).
-
Experience Replay (Optional): Stores past transitions to improve learning stability.
Data Flow & Feedback Loops
-
The agent observes the current state.
-
It selects an action based on its policy.
-
The environment transitions to a new state and returns a reward.
-
The agent updates its policy using the reward signal.
-
The cycle repeats until convergence.
Integration with Traditional Systems
RL can enhance existing systems:
-
Hybrid AI: Combining supervised learning (for predictions) with RL (for decision-making).
-
Human-in-the-Loop RL: Allowing human feedback to refine policies.
Choosing the Right RL Algorithm
Common Algorithms
|
Algorithm |
Best For |
Key Feature |
|
Q-Learning |
Discrete actions |
Off-policy, tabular |
|
Deep Q-Network (DQN) |
High-dimensional states |
Uses neural networks |
|
Policy Gradients (REINFORCE) |
Continuous actions |
Direct policy optimisation |
|
Proximal Policy Optimisation (PPO) |
Stable training |
Clipped the objective for reliability |
|
Actor-Critic (A3C, A2C) |
Balance bias & variance |
Combines value & policy methods |
Factors Influencing Choice
-
Action Space: Discrete (Q-Learning) vs. continuous (PPO).
-
State Space: Low-dimensional (tabular methods) vs. high-dimensional (Deep RL).
-
Training Stability: PPO is more stable than vanilla policy gradients.
-
Computational Resources: Simpler methods require less computing.

Case Studies & Real-World Applications
- Autonomous Systems (Self-Driving Cars)
-
Problem: Navigating dynamic environments safely.
-
Solution: RL agents learn driving policies from simulated & real-world data.
-
Algorithm: Deep Deterministic Policy Gradients (DDPG).
- Resource Optimization (Data Center Cooling)
-
Problem: Reducing energy costs while maintaining cooling efficiency.
-
Solution: Google’s RL system reduced cooling costs by 40%.
-
Algorithm: Model-based RL with neural networks.
- Recommendation Systems (Personalised Content)
-
Problem: Maximising user engagement over time.
-
Solution: RL optimises recommendations based on user interactions.
-
Algorithm: Contextual Bandits + RL.
- Robotics & Industrial Automation
-
Problem: Teaching robots complex manipulation tasks.
-
Solution: RL + imitation learning speeds up training.
-
Algorithm: Soft Actor-Critic (SAC).
Future of RL-Driven Systems
-
RL + Large Language Models (LLMs)
-
Auto-GPT & Agentic Systems: LLMs act as planners, while RL refines actions.
-
AutoRL & Self-Improving Agents
-
Automated Hyperparameter Tuning: RL optimises its learning process.
-
Meta-Learning: Agents adapt quickly to new tasks.
-
Multi-Agent Reinforcement Learning (MARL)
-
Swarm Intelligence: Multiple RL agents collaborate (e.g., traffic control).
-
Competitive Environments: AI agents in gaming & economics.

Conclusion of Building an RL-Driven System
Building RL-driven systems requires a solid understanding of core concepts—such as agents, environments, and reward mechanisms—along with careful algorithm selection tailored to the problem's constraints. A well-designed architecture must incorporate efficient feedback loops and leverage simulations before real-world deployment to significantly enhance performance and reliability.
Staying updated on advancements like AutoRL and Multi-Agent Reinforcement Learning (MARL) ensures that systems remain cutting-edge. As RL continues to evolve, integrating large language models (LLMs), robotics, and automated decision-making will unlock transformative possibilities. By adhering to these best practices, developers can create adaptive, intelligent systems capable of continuous learning and improvement, paving the way for next-generation AI solutions.


























