Reinforcement Learning (RL) is a branch of machine learning where agents learn by trial and error, using feedback from their environment to guide future actions. At the heart of this process is the concept of reward: agents receive positive or negative reinforcement based on their actions, thereby shaping their learning trajectory. Over time, this allows them to identify the most effective strategies for achieving specific goals, even in complex or dynamic environments.
Self-learning agents powered by RL are already driving innovation across industries—from robotics and supply chain optimisation to autonomous vehicles and personalised recommendations. Unlike supervised learning, RL does not require labelled datasets. Instead, agents discover optimal policies through a balance of exploration and exploitation, making it ideal for real-time applications where conditions can change frequently.
The rise of Self-Learning Agents with Reinforcement Learning signals a shift toward more adaptive, resilient, and intelligent systems. These agents can operate in uncertain environments, handle multi-step decision-making processes, and self-correct based on feedback loops. As enterprises seek to automate complex workflows and achieve higher operational efficiency, reinforcement learning provides a robust framework for building agents that learn, adapt, and evolve without constant human intervention.
This blog explores how self-learning agents with RL work, their key components, and real-world applications.
Key Insights
Self-Learning Agents with Reinforcement Learning autonomously improve decisions by learning from feedback in dynamic environments.
Policy Optimization
Learns the best action strategies through trial and error to maximize cumulative rewards over time.
Reward-Based Learning
Continuously updates decisions based on positive or negative outcomes received from the environment.
Exploration vs Exploitation
Balances trying new actions with leveraging known strategies to enhance long-term performance.
Adaptive Decision-Making
Adjusts to changing conditions without manual intervention by learning directly from environment feedback.
Overview of Autonomous Agents and the Significance of Self-Learning in Modern AI Systems
Autonomous agents are intelligent entities designed to perceive their environment, make independent decisions, and take actions to achieve specific goals. Unlike static automation scripts, these agents adapt to new situations, learn from experience, and continuously improve performance. The ability to self-learn is crucial for modern AI systems because it enables:
-
Adaptation to dynamic and unpredictable environments
-
Optimization of processes without constant human intervention
-
Scalability across diverse use cases, from industrial automation to digital customer service
Understanding Reinforcement Learning (RL)
Reinforcement Learning (RL) is a machine learning paradigm in which agents learn to make optimal decisions by interacting with their environment and receiving feedback as rewards or penalties. The process is inspired by behavioural psychology and mirrors how humans and animals learn through trial and error.
 Fig 1. How Reinforcement Learning Agents Interact with Their Environment
Fig 1. How Reinforcement Learning Agents Interact with Their Environment Concepts in RL
-
Agent: The core decision-maker that takes actions to achieve specific objectives.
-
Environment: The system or world in which the agent operates.
-
State: The current situation or context as perceived by the agent.
-
Action: The set of possible moves or decisions the agent can make.
-
Reward: The feedback signal indicating an action's immediate benefit or cost.
-
Policy: The agent's strategy to determine its next move based on the current state.
-
Value Function: An estimate of future cumulative rewards from a given state.
This feedback loop allows the agent to iteratively refine its policy, aiming to maximise long-term rewards. For example, an RL agent in a supply chain environment might learn to optimise logistics routes for cost savings and efficiency by continuously adapting to real-world variables.
By unifying the RL lifecycle from environment simulation to model deployment, NexaStack provides a robust foundation for organisations to innovate faster while maintaining complete control over data security and infrastructure scalability. This branded, composable platform is purpose-built for regulated industries and AI-native startups seeking to operationalise RL agents at scale.
How RL Powers Intelligent Self-Learning Agents
Reinforcement Learning empowers agents to become truly intelligent by allowing them to learn and adapt through continuous interaction with their environment. Rather than relying on static instructions, RL agents use feedback loops to refine their strategies to maximize long-term rewards. This approach makes self-learning agents highly effective in dynamic, real-world scenarios where adaptability is critical.
The Power of Feedback Loops
At the core of RL is the feedback loop: agents take actions, observe the outcomes, and adjust their policies based on the rewards received. Over time, this process leads to smarter, more autonomous behaviour, enabling agents to handle complex tasks such as resource allocation, process automation, and real-time decision optimisation.
Orchestrating RL Training with NexaStack
NexaStack enhances RL workflows by providing:
-
Automated feedback collection: The platform captures reward signals and performance metrics in real time, ensuring agents receive immediate, actionable feedback for every decision.
-
End-to-end training orchestration: NexaStack manages the entire RL pipeline, from environment simulation to agent evaluation, reducing manual overhead and accelerating experimentation.
-
Real-time monitoring and analytics: Integrated dashboards deliver insights into episode rewards, policy improvements, and agent performance, supporting data-driven iteration.
-
Secure, policy-driven environments: All training and deployment occur within enterprise-grade infrastructure, ensuring compliance and protecting sensitive data.

RL Algorithm Types and When to Use Them
Reinforcement Learning offers diverse algorithms, each suited to different types of problems and environments. Selecting the right approach is crucial for maximizing agent performance and training efficiency.
Value-Based Algorithms
Examples: Q-Learning, Deep Q-Networks (DQN)
Value-based methods estimate the value of a particular action in a given state. These algorithms are ideal for environments with discrete action spaces and are widely used for game playing and robotic navigation tasks.
-
Best for: Discrete action spaces, model-free environments
-
NexaStack compatibility: Easily implemented using Ray RLlib or Stable Baselines3 within NexaStack’s containerized ecosystem.
Policy-Based Algorithms
Examples: REINFORCE
Policy-based methods directly optimize the agent’s policy without estimating value functions. These are well-suited for continuous action spaces and scenarios requiring stochastic policies.
-
Best for: Continuous action spaces, stochastic or highly variable environments
-
NexaStack compatibility: Seamlessly integrated with TensorFlow and PyTorch via the NexaStack SDK.
Actor-Critic Algorithms
Examples: PPO (Proximal Policy Optimization)
Actor-critic methods combine the strengths of value-based and policy-based approaches, offering stability and scalability for complex tasks. These algorithms are commonly used for large-scale, real-world applications.
-
Best for: Large-scale, complex environments requiring stable and efficient learning
-
NexaStack compatibility: Supported through OpenAI Gym, Ray RLlib, and BYOC (Bring Your Own Container) flexibility.
Seamless Integration with RL Libraries
NexaStack offers broad compatibility with leading RL frameworks and libraries. Whether you are using Stable Baselines3, Ray RLlib, or custom algorithms built in PyTorch or TensorFlow, NexaStack’s SDK and BYOC architecture ensure that you can deploy, monitor, and scale RL workloads efficiently within a secure, enterprise-grade environment.
Deploying RL Workloads on NexaStack
Effectively deploying reinforcement learning (RL) workloads requires a platform that can handle distributed training, real-time monitoring, and pipeline automation—all while ensuring enterprise-grade security and scalability. NexaStack is purpose-built for these needs, providing a seamless RL development and deployment environment.
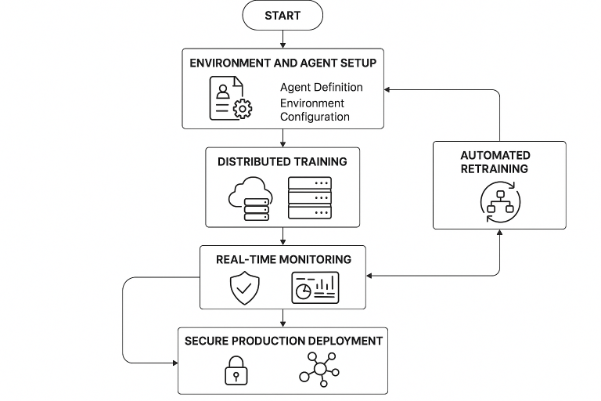 Fig 2. End-to-End Workflow for Deploying RL Agents with NexaStack
Fig 2. End-to-End Workflow for Deploying RL Agents with NexaStackStep-by-Step Guide to RL Deployment
1. Run Distributed Training
Leverage NexaStack’s private cloud infrastructure to launch distributed RL training jobs. The platform dynamically allocates compute resources, enabling you to scale up experiments for faster convergence and more robust model evaluation.
-
Launch containerized RL workloads using frameworks like Ray RLlib or Stable Baselines3.
-
Use BYOC (Bring Your Own Container) to integrate custom environments and algorithms.
NexaStack offers real-time dashboards and observability tools that help you:
-
Track episode rewards, agent performance, and training metrics as experiments progress.
-
Visualise policy improvements and convergence trends, making identifying bottlenecks or opportunities for further optimisation easy.
Automate the entire RL pipeline from data ingestion to model retraining using NexaStack’s agent lifecycle management features:
-
Schedule recurring training jobs and automate model evaluation.
-
Integrate with CI/CD workflows for continuous delivery of improved RL agents.
-
Ensure compliance and privacy by keeping all data and computing within secure enterprise boundaries.
Use Cases of Self-Learning Agents with NexaStack
Self-learning agents powered by reinforcement learning are transforming diverse industries by automating complex processes, optimising operations, and enabling real-time decision-making. NexaStack’s secure, AI-native platform provides the foundation for deploying these agents at scale, ensuring privacy, compliance, and operational efficiency.
Autonomous Process Automation
-
IT and Operations: NexaStack enables organisations to automate repetitive IT support and operations tasks, improving efficiency, reducing manual intervention, and faster incident resolution. AI agents can monitor systems, detect anomalies, and proactively resolve issues, freeing teams to focus on higher-value activities.
-
Business Workflows: Enterprises leverage NexaStack’s orchestration to manage end-to-end business processes, from customer service ticketing to supply chain management. Self-learning agents adapt to workflow changes, optimise resource allocation, and continuously refine automation strategies.
Financial Market Simulations
-
Trading Optimization: Financial institutions use NexaStack to deploy RL agents for real-time trading, risk management, and market simulation. These agents analyse vast market data, adapt to changing conditions, and execute trades with improved speed and accuracy, all within a secure, compliant infrastructure.
-
Fraud Detection: RL-powered agents can simulate and detect fraudulent activities by monitoring real-time transactions, identifying anomalies, and triggering alerts for further investigation.

Overcoming Challenges in RL Deployment
Deploying reinforcement learning (RL) in enterprise environments comes with unique challenges, from managing compute resources to ensuring regulatory compliance and scaling efficiently. NexaStack addresses these obstacles with an agent-first, AI-native architecture designed for secure, scalable, and observable RL operations.
Compute Resource Management
NexaStack AI uses intelligent scheduling and auto-scaling to allocate computing resources dynamically, ensuring efficient use of GPUs and CPUs. With Xenoinify AI Cost Optimisation, organisations can monitor and control resource spending, turning infrastructure into a value driver.
-
Scalability Bottlenecks
NexaStack’s agentic infrastructure, featuring SAIF Aviator, enables seamless auto-scaling of multi-agent systems across private cloud, hybrid, and edge environments. This ensures RL workloads scale effortlessly from pilot to production, maintaining compliance and data sovereignty.
-
Data Pipeline Complexity
With Agent SRE, NexaStack provides real-time observability and troubleshooting for agent behaviour. Integrated policy-as-code, LLMOps, and a unified model catalogue streamline compliance, versioning, and lifecycle management—simplifying RL deployments from experimentation to production.
Tools and Frameworks Supported by NexaStack for RL
A successful reinforcement learning (RL) deployment relies on seamless integration with industry-leading tools and frameworks. NexaStack is designed as an open, containerized, AI-native ecosystem, supporting a wide range of RL libraries and machine learning frameworks to accelerate experimentation and production.
Supported RL Libraries
-
OpenAI Gym: The de facto standard for developing and benchmarking RL algorithms, enabling rapid prototyping of custom environments.
-
Ray RLlib: A scalable RL library for distributed training, perfect for large-scale, multi-agent experiments.
-
Stable Baselines3: A popular collection of high-quality RL implementations, ideal for research and fast iteration.
NexaStack Integration Highlights
-
NexaStack SDK: Simplifies integration with custom RL models and environments, supporting both open-source and proprietary codebases.
-
Bring Your Own Container (BYOC): Deploy any RL library or framework within NexaStack’s secure, enterprise-grade infrastructure.
-
Unified Observability: Monitor, debug, and optimize RL workloads across all supported frameworks using NexaStack’s integrated dashboards and analytics.

Case Study: RL-Based Decision Optimization Using NexaStack
To illustrate Nexastack's real-world impact, let’s explore a practical case study involving RL-based decision optimization in the energy sector.
Scenario: Smart Energy Grid Optimization
A leading utility company aimed to optimize energy distribution across a smart grid by deploying reinforcement learning agents. The goals were to minimize energy loss, balance supply and demand in real time, and reduce operational costs while maintaining strict regulatory compliance.
Solution Implementation with NexaStack
-
Custom RL Environment: Using OpenAI Gym integrated within NexaStack’s secure infrastructure, the team simulated a digital twin of the energy grid, allowing agents to experiment with different distribution strategies in a risk-free environment.
-
Distributed Training: The company leveraged Ray RLlib on NexaStack’s private cloud to run large-scale, distributed RL training jobs. Auto-scaling and intelligent resource management ensured efficient compute usage and cost control.
-
Real-Time Monitoring: NexaStack’s unified observability tools enabled the team to monitor episode rewards, convergence trends, and agent performance in real time, supporting rapid iteration and troubleshooting.
-
Automated Pipelines: The deployment pipeline was automated using NexaStack’s agent lifecycle management, allowing continuous retraining and deployment of improved RL agents as new data became available.
Results and Impact
-
Operational Efficiency: The RL agents achieved a measurable reduction in energy loss and improved grid stability, resulting in significant cost savings.
-
Scalability: NexaStack’s platform allowed the utility to scale from pilot simulations to full production deployment without infrastructure bottlenecks.
-
Compliance and Security: All sensitive operational data remained within the company’s private cloud, ensuring compliance with industry regulations.
Future-Proofing Agentic AI with NexaStack
As agentic AI systems become more advanced and collaborative, organisations need platforms that can adapt and scale with future demands. NexaStack is purpose-built to support this evolution, offering a modular, composable architecture that makes it easy to integrate new technologies and deploy multi-agent systems.
With features such as auto-scaling, agent-first infrastructure, and enterprise-grade security, NexaStack ensures that your AI workloads remain secure, compliant, and efficient as your needs evolve. Its support for multi-agent collaboration and seamless integration with leading AI tools means your organisation is always ready to leverage the latest advancements in intelligent automation.
By choosing NexaStack, enterprises can confidently build and scale the next generation of adaptive, agentic AI systems—staying ahead in a rapidly evolving digital landscape.

Conclusion: Building the Next Generation of Autonomous Systems
Self-learning agents powered by reinforcement learning redefine what’s possible in automation, optimisation, and intelligent decision-making. By leveraging Nexastack's secure, scalable, and modular capabilities, organisations can confidently deploy, monitor, and scale these advanced agents across private cloud, edge, and hybrid environments. With its agent-first architecture, robust observability, and seamless integration with leading AI frameworks, NexaStack empowers enterprises to accelerate innovation, maintain compliance, and future-proof their AI infrastructure.
Frequently Asked Questions (FAQs)
Advanced FAQs on Self-Learning Agents powered by Reinforcement Learning.
How do self-learning agents optimize decisions over time?
They learn through continuous feedback loops, updating policies based on rewards from real or simulated environments.
What makes reinforcement learning suitable for autonomous agents?
It enables agents to explore actions, evaluate outcomes, and adapt strategies dynamically without predefined rules.
How do agents prevent unsafe or biased learning behaviors?
Through constrained reward functions, safety filters, and human-in-the-loop evaluation during policy updates.
Can reinforcement learning scale to multi-agent systems?
Yes — coordinated learning, shared rewards, and decentralized policies enable robust multi-agent collaboration.

























