AI infrastructure, large language model (LLM) pipelines, reliable LLM deployment, private cloud inference, data privacy, secure orchestration, and scalable AI workflows—these key concepts shape the foundation of modern enterprise AI. NexaStack’s private cloud platform provides enterprises with a robust environment for deploying, monitoring, and governing powerful LLMs within secure, compliant boundaries, while maximizing performance and reducing latency.
The surge in AI adoption across industries demands LLM pipelines that are not only powerful but also reliable, secure, and robust. Enterprises require platforms like NexaStack to seamlessly build and manage their private cloud inference workloads, ensuring data privacy, regulatory compliance, operational transparency, and real-time performance optimization. This blog explores the critical components of building reliable LLM pipelines, the benefits of running inference on private clouds, and how NexaStack enables enterprises to meet these challenges with confidence.
Why Reliability Matters in LLM Pipelines
Reliability in LLM pipelines ensures predictable and consistent AI performance, which is crucial for high-stakes applications such as financial risk analysis, healthcare diagnostics, and automated manufacturing processes. Unreliable models can lead to costly downtime, inaccurate predictions, and penalties for non-compliance.
Building a pipeline with high availability and fault tolerance:
-
Maintains consistent latency even during traffic spikes.
-
Permits automatic failover and model rollback to mitigate disruptions.
-
Ensures repeatable, auditable prediction outcomes necessary for accountability.
This foundation enables enterprises to foster trust among users and stakeholders, thereby increasing the adoption of AI-driven decisions. Studies show that pipelines optimized for reliability reduce operational costs while enhancing user satisfaction and compliance adherence.
The Role of Private Cloud Inference with NexaStack
Private cloud inference shifts AI workloads from public clouds to dedicated, enterprise-controlled infrastructure. This offers critical advantages:
-
Enhanced data security by restricting access within the organization’s firewall.
-
Simplified compliance with data residency and industry regulations such as GDPR and HIPAA.
-
Greater control over compute resources and cost predictability.
-
Ability to customize infrastructure aligned with specific enterprise policies.
NexaStack uniquely simplifies private cloud LLM deployments by automating model lifecycle management, orchestrating workloads on GPU clusters, and integrating with enterprise identity and access management systems. Together, these features deliver an enterprise-grade AI inference environment designed for scalability, security, and compliance.
Common Challenges in Building LLM Pipelines
Designing reliable LLM pipelines is complex and involves overcoming several hurdles:
In many organizations, multiple teams and diverse data sources complicate pipeline workflows. Ensuring secure, real-time data flows requires advanced integration mechanisms.
Performance bottlenecks often arise from GPU scheduling inefficiencies or delays in data preprocessing. Without automated monitoring, detecting model drift or performance degradation can be challenging, threatening prediction accuracy.
Additionally, staying compliant across different regulatory regimes demands fine-grained policy enforcement and transparent audit trails.
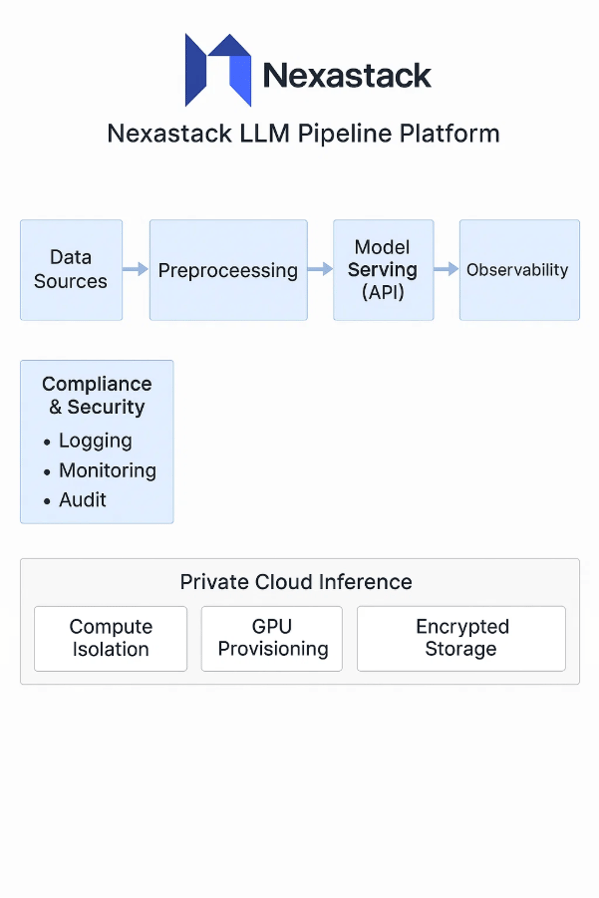
Data Privacy and Compliance Concerns
Protecting sensitive data is paramount when deploying LLMs that process personal or confidential information. Regulations such as GDPR enforce strict rules on data storage, access, and usage.
Private clouds incorporated with NexaStack provide:
-
Role-based access controls tie permissions directly to user identity.
-
Encrypted data storage and transport ensure confidentiality.
-
Immutable audit logs for comprehensive activity tracking.
-
Automated enforcement of compliance rules to minimize manual oversight.
Latency and Performance Bottlenecks
The real-time nature of many LLM applications demands ultra-low latency inference. However, processing large models often requires complex GPU scheduling and efficient data pipelines.
NexaStack tackles these issues by:
-
Utilizing GPU-aware workload orchestration that maximizes parallelism.
-
Implementing kernel fusion techniques to reduce inference runtime.
-
Providing detailed telemetry on token-level latency to fine-tune deployments.
-
Autoscaling resources dynamically based on usage to maintain consistent responsiveness.
Together, these design elements ensure scalable AI applications can meet productivity demands without sacrificing speed.
Observability and Governance Gaps
Without sufficient observability, organizations risk missing early signs of model performance degradation or non-compliance.
NexaStack delivers comprehensive governance through:
-
Centralized dashboards exposing resource utilization, accuracy metrics, and latency.
-
Version-controlled models enabling auditability and rollback.
-
Explainability tools to elucidate model predictions for regulatory and business transparency.
-
Automated bias detection mechanisms reduce ethical risks.
Such visibility supports proactive issue mitigation, maintaining pipeline health, and compliance.
NexaStack for LLM Pipeline Reliability
Context-First Agent Infrastructure
NexaStack’s architecture prioritizes context management in AI workflows, enabling:
-
Handling complex user interactions with multi-turn conversations.
-
Dynamic adjustment of workflows based on real-time inputs.
-
Integration with heterogeneous enterprise APIs for enriched outputs.
This design empowers teams to build intelligent, adaptive LLM applications aligned with business logic.
Built-In Orchestration and Automation
Seamless orchestration of LLM pipelines via NexaStack includes:
-
Kubernetes-native automation reduces manual configuration.
-
Continuous Integration/Continuous Deployment (CI/CD) pipelines are speeding updates.
-
Auto-scaling features balance load and cost-effectiveness.
These capabilities enable reliable and repeatable deployment cycles, which are essential for enterprise adoption.
Guardrails for Compliance and Security
Security guardrails embedded into NexaStack workflows include:
-
Automated detection and blocking of potential data leaks.
-
Enforced multi-tenant isolation to protect workload integrity.
-
Real-time logging aligned with audit and compliance standards.
Guardrails ensure organizations can scale AI responsibly without exposing themselves to undue risk.
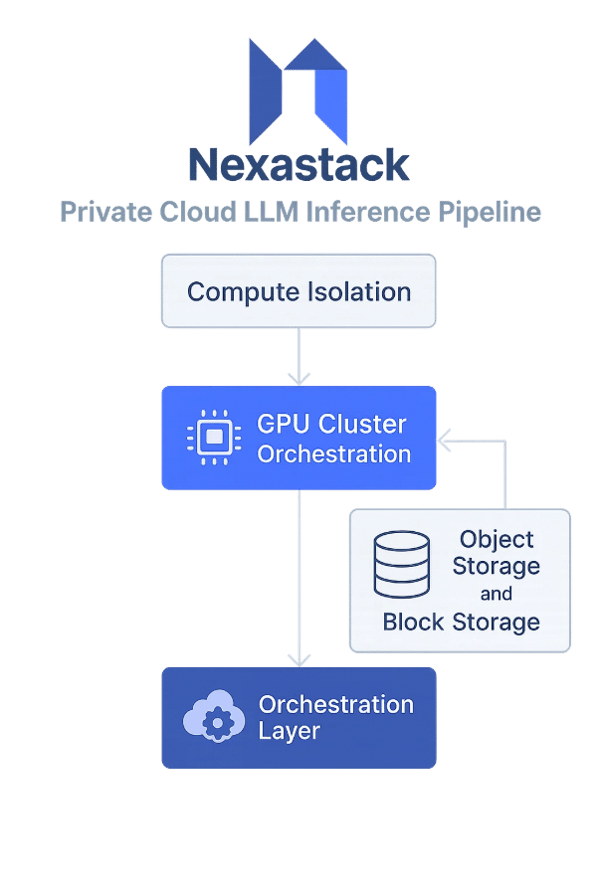
Designing Private Cloud Inference Pipelines
Architecture Overview
Modern LLM pipelines built with NexaStack combine modular components optimized for performance and security:
-
GPU cluster orchestration for efficient compute utilization.
-
Object and block storage for handling encrypted datasets.
-
Automated data ingestion and preprocessing for pipeline flexibility.
Integration with Enterprise Data Sources
Effective integration connects heterogeneous data sources, including relational databases, knowledge bases, and unstructured file systems, to facilitate seamless data access and analysis. NexaStack’s connectors enable secure and reliable ingestion with preprocessing capabilities, speeding up model readiness and improving data fidelity.
Isolation for Secure and Scalable Deployments
Ensuring the separation and isolation of sensitive workloads across multiple tenants is critical. NexaStack uses network segmentation, encrypted volumes, and dedicated GPU provisioning to uphold security while supporting flexible scaling policies
Key Stages of Reliable LLM Pipelines
Building a reliable Large Language Model (LLM) pipeline involves carefully orchestrated stages that ensure data quality, efficient inference, and continuous improvement. Each stage addresses critical technical and operational challenges to deliver high-performance AI solutions.
Data Preparation and Preprocessing
Data preparation is the first and arguably most crucial step in constructing an LLM pipeline. Raw text data originates from diverse sources, including documents, web pages, databases, and APIs, and is available in various formats, such as PDFs, HTML, JSON, and CSV. Preprocessing aims to transform this uncontrolled raw data into clean, consistent, and structured input.
Key activities include:
-
Data cleansing: Removing duplicate entries, correcting errors, and filtering out irrelevant or low-quality content like spam or toxic language. This step improves overall data integrity and reduces noise.
-
Normalization: Standardizing formats and encodings (e.g., UTF-8), handling whitespace, punctuation, and special characters to ensure consistency.
-
Tokenization: Breaking text into tokens (words, subwords, or characters) suitable for model input, often using methods like Byte Pair Encoding (BPE) or WordPiece.
-
Feature Engineering: Generating representations such as embeddings or adding metadata to enrich text semantics for downstream tasks.
-
Data validation: Ensuring that the data adheres to expected patterns and domain-specific rules, such as domain language or syntactic correctness.
Preprocessing pipelines are often modular and scalable, accommodating both batch and streaming data, and integrating with LLM frameworks like Hugging Face. Tools like Apache Spark or custom Python scripts can orchestrate these workflows efficiently, applying automated quality checks to maintain dataset health.
Properly prepared data eliminates inconsistencies, reduces model training time, and significantly improves inference accuracy, setting a robust foundation for subsequent LLM stages.
Model Routing and Inference Optimization
Model routing refers to the intelligent selection and dispatching of inference requests to the most appropriate LLM model variant. Large enterprises typically maintain different models or fine-tuned versions optimized for specific tasks, languages, or domains.
Key considerations include:
-
Dynamic routing: Redirecting queries based on input type, user context, or desired accuracy-latency trade-offs, enabling efficient utilization of model resources.
-
Hardware-aware scheduling: NexaStack schedules inferences with awareness of GPU/CPU capabilities, memory constraints, and load, ensuring minimal latency and maximum throughput.
-
Batch vs. streaming inference: Balancing throughput and delay by grouping predictions when possible or serving low-latency real-time requests independently.
-
Kernel fusion and quantization: Reducing compute overhead by optimizing operations and using lower-precision arithmetic without compromising model quality.
By combining these techniques, NexaStack maximizes hardware utilization, accelerates response time, and handles variable workload patterns efficiently.
Monitoring, Drift Detection, and Feedback Loops
Continuous monitoring is crucial for maintaining model quality and operational reliability over time. Model drift—changes in data distribution or user behavior—can degrade performance if left unchecked.
Cross-Team Benefits of NexaStack
Effective LLM pipeline management requires collaboration across multiple functions—data science teams build and fine-tune models, DevOps manages deployment and scaling, and compliance teams oversee regulations and data governance.
NexaStack functions as a centralized platform offering:
-
Shared dashboards and alerts: Unified visibility into model performance, system health, and compliance status across teams, reducing information silos.
-
Reusable pipeline templates and automation: Streamlining deployment and experimentation with continuous integration and continuous delivery (CI/CD), reducing manual errors and speeding updates.
-
Unified traceability: End-to-end lineage tracking supports audit readiness and simplifies troubleshooting by linking data sources, models, predictions, and system events.
By bridging communication and operational gaps, NexaStack enables enterprises to accelerate AI initiatives, enhance efficiency, and reduce time to value.
Use Cases and Applications
Finance
In financial services, NexaStack-powered LLMs automate complex, regulatory-sensitive workflows such as:
-
Regulatory document parsing and compliance verification.
-
Anti-money laundering (AML) transaction monitoring.
-
Know Your Customer (KYC) identity verification.
By operating on a private cloud, sensitive financial data remains secure, meeting strict compliance requirements and avoiding data leakage risks.
Healthcare
Healthcare providers use secure LLM applications for:
-
Clinical decision support by summarizing electronic health records (EHRs).
-
Patient triage and appointment scheduling automation.
-
Medical transcription and documentation support.
These applications adhere to HIPAA regulations, preserving patient privacy while leveraging AI to improve care quality.
Manufacturing
Manufacturers improve operations through:
-
Automated extraction of procedural knowledge from manuals and logs.
-
Predictive maintenance analytics using machine data.
-
Workflow optimization through AI-driven process recommendations.
Future of LLM Pipelines in Private Cloud
The future of enterprise LLM pipelines is shaped by increasingly hybrid and multi-cloud architectures, giving organizations both flexibility and control. NexaStack’s API-first design enables seamless orchestration across diverse environments, facilitating the scalable growth of AI.
Reinforcement Learning as a Service (RLaaS) introduces adaptive capabilities that continuously optimize model routing and resource allocation, enhancing efficiency and reliability.
Autonomous LLM operations, driven by continuous retraining, federated learning, and self-healing mechanisms, promise resilient, self-managing AI pipelines that can maintain peak performance with minimal human intervention. This detailed expansion provides a thorough understanding of critical stages and benefits in building reliable LLM pipelines with NexaStack in private cloud environments.
Conclusion
Reliable, secure LLM pipelines powered by NexaStack’s private cloud inference are essential for enterprise AI success. By prioritizing modular orchestration with automated monitoring, enforcing strong compliance and privacy guardrails, and fostering cross-functional collaboration, organizations can build unified, resilient AI operations. Preparing for hybrid cloud adoption and autonomous AI evolution will further future-proof deployments. Adopting these practices positions enterprises to lead in digital transformation, AI innovation, and regulatory compliance with confidence.

























