Open-source text-to-speech (TTS) models are revolutionizing how we interact with machines through voice technology. As voice-based applications become more embedded in our daily lives—from intelligent assistants and screen readers to IVR systems and voice-enabled apps—the demand for customizable, privacy-friendly, and scalable TTS solutions is soaring. This is where open-source models are stepping in to change the game.
Unlike commercial TTS services with usage restrictions, vendor lock-ins, and recurring costs, open-source TTS platforms offer developers and researchers complete control over voice synthesis systems. Popular models like Mozilla TTS, Coqui TTS, ESPnet, and VITS provide high-quality, neural-based speech synthesis, often rivalling the performance of commercial engines. These models are free to use and modify, and support multilingual and multi-speaker capabilities, making them ideal for global and inclusive applications.
Whether you're building custom voice interfaces, working on accessibility tools, or training AI agents, open-source TTS empowers you to innovate without boundaries.
With the right tools and knowledge, you can deploy a fully functional, high-performance TTS system on your infrastructure, ensuring data privacy, scalability, and complete model transparency.
Let’s examine how open-source TTS models democratise speech technology and enable more natural and intelligent voice experiences.
Key Insights
Open-source Text-to-Speech (TTS) models are transforming speech synthesis by offering flexible, community-driven alternatives for generating natural-sounding voice outputs.
Model Flexibility
Supports fine-tuning and customization for various languages, accents, and domains.
Cost Efficiency
Eliminates licensing fees, making high-quality TTS accessible for all scales of deployment.
Community Innovation
Rapid improvements and features driven by global developer contributions.
Integration Ready
Easily embeddable into apps, devices, and services with open APIs and documentation.
Why Voice Tech Needs Open-Source TTS?
Voice technology has shifted from a futuristic concept to a core component of everyday digital interactions. With the proliferation of smart speakers, virtual assistants, and voice-enabled devices, the way consumers interact with technology is being redefined. Today, voice interfaces are integrated into:
-
Smart Homes & IoT Devices: Controlling lighting, appliances, and security systems.
-
Mobile Devices: Enhancing user engagement and accessibility through voice commands.
-
Automotive Systems: Enabling hands-free operation and enhancing safety.
-
Customer Service Platforms: Improving responsiveness with automated voice agents.
These developments highlight how voice interfaces are becoming a key touchpoint in user experience design, necessitating technologies that can deliver natural, expressive, and reliable speech.
Why Open-Source TTS Models Matter in the NexaStack Ecosystem
Open-source TTS models offer several critical advantages when implemented within NexaStack's comprehensive AI platform:
-
Customization & Flexibility: NexaStack's unified inference engine supports various machine learning frameworks, allowing developers to fine-tune TTS models to suit specific use cases, from regional accents to brand-specific tones.
-
Cost-Efficiency: Organisations can significantly reduce costs while investing more in innovation by eliminating expensive licensing fees and utilising NexaStack's resource optimisation features (automated scaling and GPU time-slicing).
-
Transparency & Trust: Open-source solutions within NexaStack's secure AI operations framework allow for complete inspection of the codebase while maintaining enforced isolation and encrypted execution environments, promoting security, ethical usage, and compliance.
-
Community-Driven Innovation: NexaStack's extensible architecture supports continuous contributions from the global open-source community, helping drive rapid advancements while ensuring enterprise-grade stability.
Open-Source vs Proprietary TTS: What to Choose?
While open-source TTS models offer significant advantages, understanding how they compare to proprietary alternatives is crucial for making informed decisions:

When NexaStack-Powered Open-Source TTS Excels:
-
Organizations with specific voice customization requirements benefit from NexaStack's support for multiple frameworks and model types
-
Projects with privacy concerns or regulatory constraints can leverage NexaStack's private cloud compute and governance framework
-
Companies with in-house technical expertise can utilize NexaStack's Infrastructure as Code (IaC) approach for streamlined deployment
-
Applications requiring deep integration with existing systems can take advantage of NexaStack's extensive connector ecosystem
When Proprietary TTS May Still Be Preferable:
-
Organizations lacking NexaStack implementation expertise and seeking turnkey solutions
-
Projects with tight timelines where NexaStack setup would add initial overhead
-
Use cases requiring immediate access to production-ready voices without customization
-
Many organisations adopt a hybrid approach—using proprietary solutions for standard applications while utilising NexaStack-powered open-source models for strategic differentiators that require unique voice characteristics or specialised functionality.
Many organisations adopt a hybrid approach—using proprietary solutions for standard applications while utilising open-source models for strategic differentiators that require unique voice characteristics or specialised functionality.
How Modern TTS Systems Work
Modern TTS systems typically comprise two core stages and various other components. 
Acoustic Modeling:
-
Text Processing: Converts written text into a phonetic or linguistic representation.
-
Spectrogram Generation: Uses sequence-to-sequence models to map text to a visual representation of sound frequencies over time.
Vocoder:
-
Waveform Synthesis: Converts spectrograms into audible waveforms. Modern vocoders like WaveNet, Parallel WaveGAN, or HiFi-GAN produce natural-sounding audio with high fidelity.
-
Attention Mechanisms: Help align text with corresponding speech features, ensuring the timing and emphasis are correct.
-
Prosody and Emotion Controls: Advanced systems now integrate modules to modulate tone and emotion, delivering contextually appropriate speech.
Notable Recent Breakthroughs
Recent advancements in the field include:
-
Zero-Shot Voice Cloning: Recent breakthroughs allow models to clone voices with minimal training data, opening up new applications in personalised voice synthesis.
-
Enhanced Emotional Control: New architectures now permit nuanced control over speech emotion, enabling synthetic voices to convey joy, sadness, or urgency.
-
Scalable Inference Frameworks: Innovations such as BentoML integration are streamlining deployment, allowing even small organizations to implement TTS in production with ease.
Comprehensive Guide to Open-Source TTS Libraries
For developers and organizations eager to experiment with TTS, a variety of libraries and frameworks are available:
XTTS-v2 on NexaStack
-
Implementation: NexaStack's multi-framework support enables efficient deployment of XTTS-v2's voice cloning capabilities across 17 languages.
-
Optimization: The platform's resource scheduling ensures low latency of emotion and style transfer operations.
-
Use Cases: Multilingual voice cloning, personalised virtual assistants, and audiobooks with unified governance.
ChatTTS with NexaStack
-
Implementation: NexaStack's inference capabilities optimize ChatTTS for conversational applications.
-
Scaling: The platform's auto-scaling features handle dynamic loads for dialogue-friendly speech generation.
-
Use Cases: Enterprise virtual assistants and interactive dialogue systems with controlled access.
MeloTTS & OpenVoice v2 Deployment
-
Implementation: NexaStack's edge computing support enables real-time inference for MeloTTS across multiple languages.
-
Integration: The platform's API ecosystem facilitates OpenVoice v2's zero-shot voice cloning integration with existing enterprise systems.
-
Use Cases: Customer service bots and immersive experiences with comprehensive monitoring.
Industrial Applications of TTS Technology
Voice-driven technology is revolutionizing industries far beyond customer service. In manufacturing, healthcare, transportation, retail, finance, education, and media production, TTS models improve efficiency, accessibility, and user experience.
TTS systems automate voice-controlled operations in manufacturing and production environments. Factories integrate these systems to provide real-time feedback on machinery performance.
-
Healthcare is another domain where TTS technology makes a significant impact. Hospitals and clinics employ TTS to deliver appointment reminders, medication instructions, and diagnostic reports.
-
Transportation and logistics have also embraced TTS solutions. Modern vehicles have voice-enabled navigation systems that give drivers real-time updates on routes, traffic conditions, and safety alerts.
-
Voice technology is transforming the shopping experience in retail and e-commerce. Companies use virtual assistants powered by TTS to help customers navigate online stores.
-
Financial services and banking have similarly benefited from TTS integration. Banks deploy interactive voice response (IVR) systems that guide customers through routine transactions.

TTS as a Business Differentiator
Voice is not just a technological tool; it is emerging as a strategic business asset. A distinctive voice can define a brand’s identity and create lasting impressions on customers. Companies that invest in developing a custom voice—through tailored TTS solutions—benefit from enhanced engagement, improved accessibility, and significant competitive differentiation.
Building a brand identity through voice involves more than just generating speech. It means crafting a unique auditory experience that resonates with customers. A custom voice can convey the company’s values and personality, reinforcing brand recognition and trust. For instance, a warm and friendly tone can make interactions feel more personal, while a clear and authoritative voice can instil confidence in financial or healthcare settings.
TTS technology also enriches the customer experience. When users interact with systems that communicate in a natural, human-like manner, their engagement levels increase. This improved interaction not only boosts customer satisfaction but also helps build long-term loyalty. Moreover, voice interfaces enable companies to serve a broader audience, including those with accessibility challenges, thereby expanding the customer base.
Strategic differentiation in the marketplace is another compelling reason to adopt advanced TTS solutions. With many companies still reliant on generic, one-size-fits-all voice systems, an organization that invests in a unique, high-quality voice can set itself apart from the competition. Additionally, by leveraging open-source TTS, businesses reduce dependency on commercial vendors, ensuring greater control over their voice technology and future-proofing their digital strategies.
For organizations planning to integrate TTS into their operations, a well-defined implementation roadmap is essential. This roadmap should include initial pilot projects to test and refine the technology, followed by full-scale integration into existing systems. Budget considerations, including initial setup costs and ongoing maintenance, must be carefully evaluated to ensure a positive return on investment. With the proper governance and adherence to best practices, companies can manage risks and maximize the strategic value of their voice assets.
How to Deploy Open-Source TTS Easily
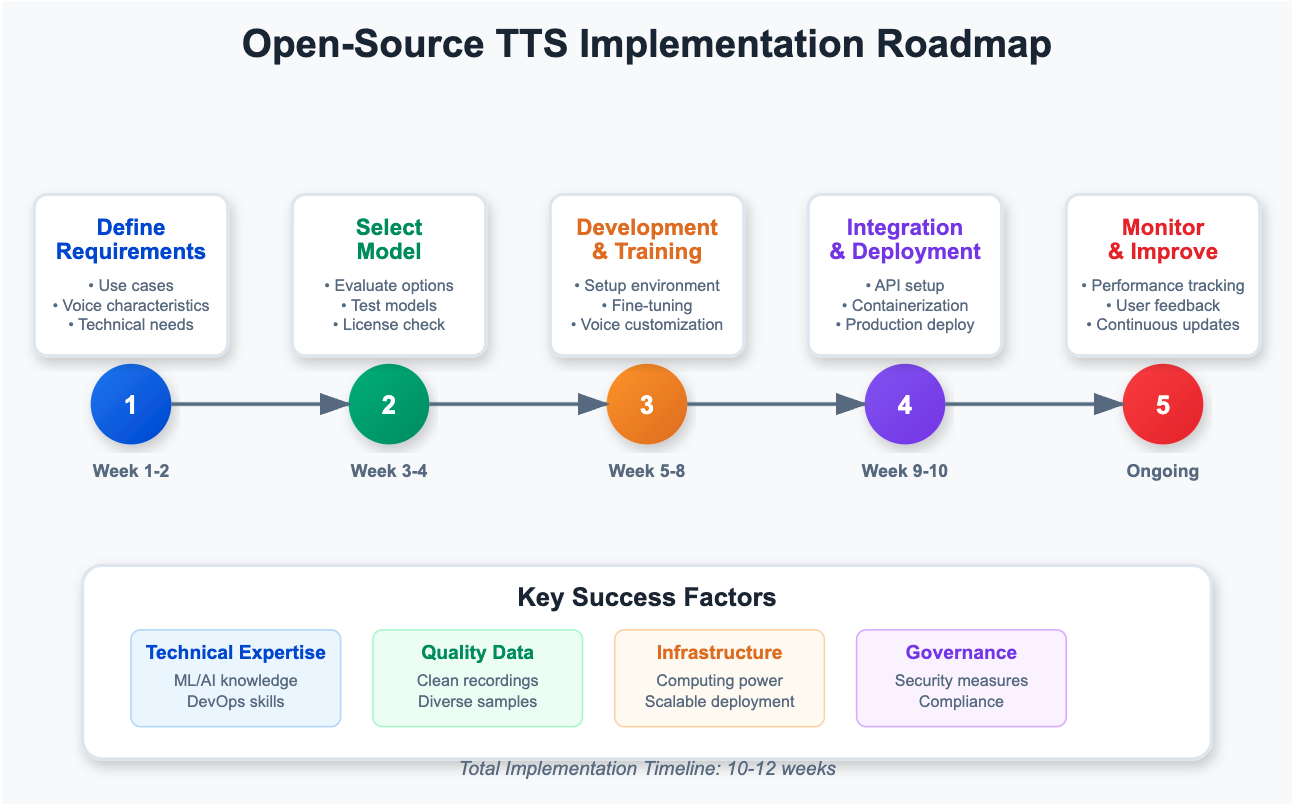 Figure 3: Roadmap for TTS Model
Figure 3: Roadmap for TTS Model - Define Your Requirements
-
Identify your specific use case (customer service, content accessibility, product enhancement)
-
Determine voice characteristics that align with your brand
-
Assess technical needs: languages, deployment environment, and resource constraints
- Select the Right Model
-
Evaluate models based on language support, voice quality, and performance
-
Test 2-3 shortlisted models with standardized scripts in Nexastack’s playground
-
Verify license compatibility with your intended use
- Development & Fine-Tuning
-
Set up a development environment with proper version control
-
For voice customization, collect 30+ minutes of high-quality recordings
-
Implement feedback loops for iterative improvement
- Integration & Deployment
-
Deploy as REST API endpoints or microservices
-
Use containerization (Docker) for consistent deployment
-
Implement caching for frequently requested phrases
- Monitor & Improve
-
Nexastack provides an in-built monitoring setup, which can be helpful in monitoring and governance.
-
Collect user feedback through in-app mechanisms
-
Schedule regular model updates as technology advances
Real-World Success: Financial Services Example
A mid-sized bank implemented OpenVoice v2 for their IVR system using Nexastack:
-
Fine-tuned with 45 minutes of professional voice recordings
-
Results: 27% reduction in call abandonment, 18% improvement in customer satisfaction
-
$1.2M annual cost savings through improved efficiency
Ethics & Legal Checks for TTS Use
As TTS technology becomes more ubiquitous, ethical and legal considerations must take center stage. One of the primary concerns is the issue of voice rights and permissions. It is crucial to ensure that any voice samples used for training or cloning are legally obtained and that the rights of individuals are respected.
-
Unauthorised voice cloning: Preventing misuse of TTS—particularly unauthorised voice cloning—is another significant challenge. Security protocols must be established to protect against potential abuses. Nexastack offers techniques like watermarking synthesized audio and implementing robust authentication systems to ensure that only authorized users have access to certain voice profiles.
-
Regulatory compliance is also critical. Organizations must stay abreast of global and regional regulations such as GDPR, which govern the use of personal data, including voice. Industry-specific standards, particularly in sectors like healthcare and finance, require adherence to strict guidelines to ensure data privacy and security.
-
Transparency in AI-driven voice applications is essential for maintaining user trust. Users should be informed when they are interacting with synthetic voices, and companies should conduct regular audits to ensure ethical practices.
Future of Open-Source TTS Models
The text-to-speech technology field continues to evolve remarkably, with several emerging trends poised to reshape how organizations leverage voice as a strategic asset in the coming years.
-
Multimodal AI Integration:The future of TTS lies in deeper integration with other AI modalities, creating more holistic experiences: Systems that can describe visual content with appropriate emotional tone and emphasis, enabling more natural interfaces for visually impaired users and more engaging content descriptions.
-
Hyper-Personalisation: Beyond simple voice cloning, next-generation systems will offer unprecedented personalisation: TTS that evolves its speaking style based on user interactions, gradually tailoring itself to individual preferences and communication patterns.
-
Edge Computing and Embedded TTS: As computational efficiency improves, powerful TTS capabilities will move to the edge. Full neural TTS models will run on smartphones and IoT devices without cloud connectivity requirements.
-
Ultra-Low Latency Systems: Real-time TTS with imperceptible delays, enabling truly conversational interfaces with natural turn-taking.
-
Synthetic Media Creation: TTS will become a foundational component of broader synthetic media ecosystems.End-to-end systems that convert written articles into narrated videos with synchronized visuals and natural voiceovers.

Conclusion of Open-Source TTS Models
Open-source TTS models implemented through NexaStack represent a groundbreaking opportunity for businesses to approach voice technology strategically. As you explore these technologies, remember that NexaStack provides the technical foundation and the governance framework for responsible and effective voice technology implementation. This comprehensive approach ensures that voice becomes a strategic differentiator in your organisation's digital transformation journey.

























