As enterprises accelerate their digital transformation journeys, the need for a unified, intelligent, and scalable AI Operating System (AI OS) has become critical. Traditional siloed systems, fragmented tools, and reactive operations can no longer support the demands of real-time decision-making, automation, and cross-functional collaboration. Designing an Enterprise AI OS offers a foundational shift, enabling organisations to orchestrate intelligent agents, leverage contextual data, and drive autonomous operations at scale.
An AI Operating System for the enterprise acts as the core layer that integrates data pipelines, model management, agent orchestration, and human-in-the-loop feedback into a cohesive and adaptive system. It bridges the gap between strategy and execution by aligning AI initiatives with business goals, ensuring data governance, and accelerating time-to-value. From finance and manufacturing to healthcare and logistics, a well-architected AI OS empowers teams to automate repetitive tasks, enhance productivity, reduce operational costs, and deliver better customer experiences.
In this blog, we’ll explore the strategic foundations of designing an enterprise-grade AI OS, the essential tools and components that make it work, and how to quantify its return on investment (ROI). Whether you're building intelligent workflows, deploying AI agents across departments, or modernising your legacy systems, understanding the blueprint of an AI Operating System will be key to unlocking enterprise-wide intelligence.
Key Insights
Designing the Enterprise AI OS involves creating an integrated foundation that aligns intelligent agents, data infrastructure, and automation with business strategy.
Strategic Alignment
Ensures AI initiatives are tied to clear business objectives and long-term value creation.
Modular Architecture
Enables flexibility and scalability through composable tools and agent-based workflows.
Unified Data Layer
Connects disparate data sources to deliver context-aware insights across the enterprise.
Measurable ROI
Tracks automation impact, cost savings, and productivity gains to justify AI investments.
Why Cost Optimisation is Critical in AI Strategy
AI has become a cornerstone of digital transformation, but its success is closely tied to how well organisations manage costs. As teams deploy larger models and more complex workflows, infrastructure spending can quickly outpace initial projections. Without a clear focus on cost optimisation, enterprises risk budget overruns, delayed projects, and diminished returns on their AI investments. Strategic cost management is essential for ensuring AI initiatives remain sustainable and deliver real business value. For more on enterprise AI infrastructure, see Google Cloud AI Infrastructure and AWS AI and ML Services.
The Hidden Expenses in Scaling AI Infrastructure
Scaling AI is rarely as straightforward as it seems. Beyond the obvious costs of hardware and software, enterprises often encounter a range of hidden expenses:
-
Data storage and transfer: Large datasets incur ongoing storage fees and bandwidth charges, especially in cloud environments.
-
Idle resources: Over-provisioned compute or storage leads to waste and unnecessary spending.
-
Manual interventions: Frequent troubleshooting and maintenance increase operational costs and slow down innovation.
-
Compliance and security: Meeting regulatory requirements can require additional tools and ongoing monitoring.
-
Vendor lock-in: Relying on a single cloud provider may limit flexibility and drive up long-term costs
Understanding the Key Cost Drivers in AI Infrastructure
Effectively managing AI infrastructure costs begins with clearly understanding what drives spending as projects scale. The most significant expenses are compute, storage, networking, and operational inefficiencies. Without a strategic approach, these costs can escalate rapidly, impacting both ROI and the ability to innovate. 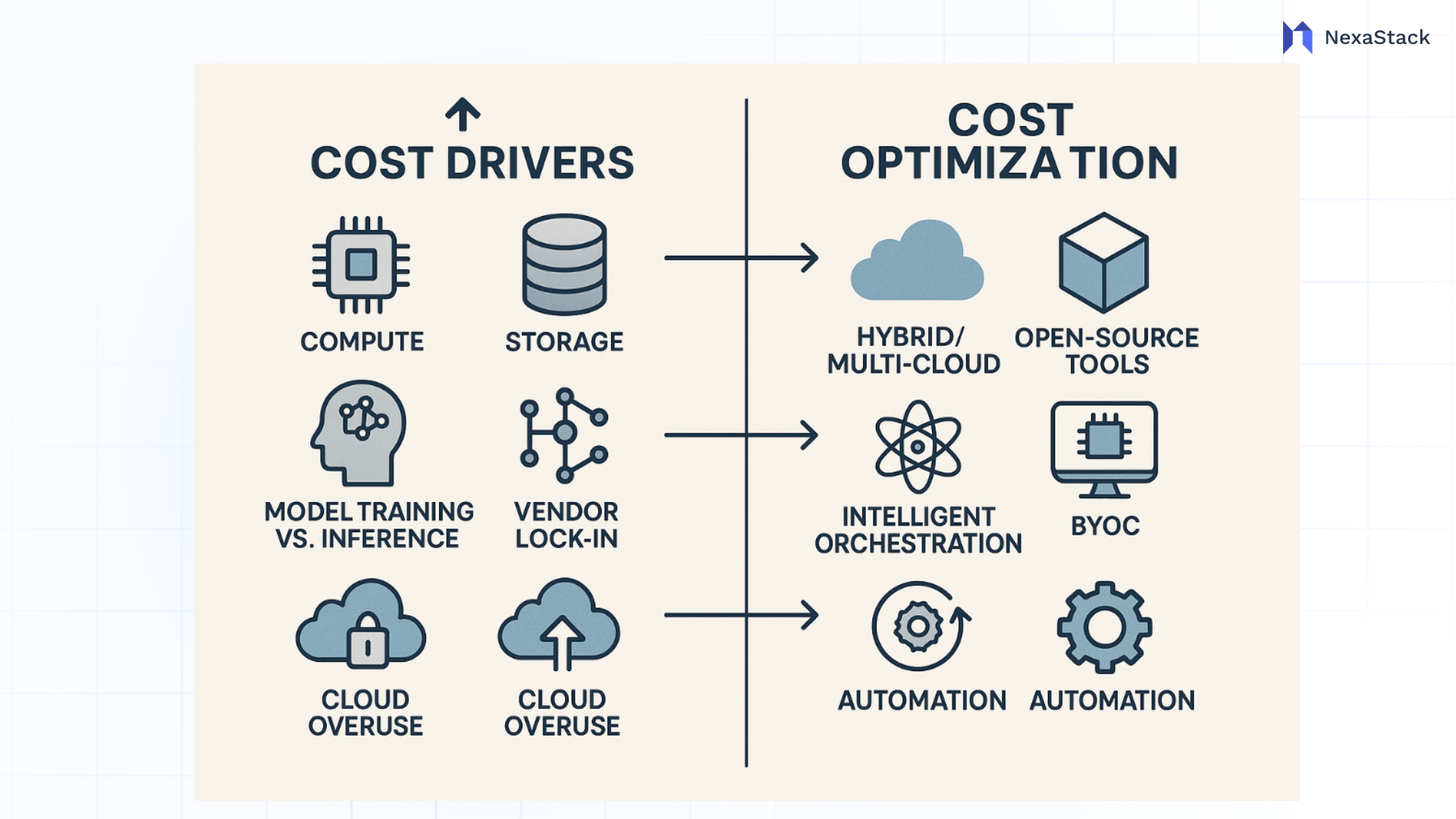
Compute, Storage, and Networking
Training advanced AI models requires powerful GPUs or TPUs, which are costly whether deployed on-premises or in the cloud. Storage needs grow as datasets expand, and maintaining high-speed, compliant storage solutions adds ongoing fees. Networking costs also increase as large volumes of data are transferred between cloud, on-premises, and edge environments.
-
Compute power: Premium-priced hardware for training and inference, such as AWS EC2 P4 Instances or Google Cloud TPUs.
-
Storage: Continuous costs for scalable, compliant data storage solutions.
-
Networking: Bandwidth and data transfer charges, especially for hybrid or multi-cloud deployments.
Model Training vs Inference Cost Balance
While model training is resource-intensive and represents a significant upfront investment, inference costs can quietly accumulate as models are deployed at scale. In many enterprise scenarios, inference accounts for most total AI lifecycle expenses.
-
Training: High, periodic compute costs for developing new models.
-
Inference: Ongoing, sometimes higher, costs for running models in production.
Vendor Lock-In and Cloud Overuse
Relying on a single cloud provider can lead to inflexible pricing, high data egress fees, and limited optimization options. Additionally, without diligent monitoring, organizations may overprovision resources or leave idle services running, resulting in hidden “shadow costs.”
-
Vendor lock-in: Proprietary technologies and pricing structures that make switching providers expensive.
-
Cloud overuse: Unmonitored or idle resources inflating monthly bills.
Strategies to Reduce AI Infrastructure Costs Effectively
Optimising AI infrastructure spending is not just about cutting corners; it’s about making smart, strategic choices that maximise value while minimising waste. Enterprises that succeed in cost optimisation use modern deployment models, open-source technologies, and intelligent automation to keep expenses under control without limiting innovation.
Leveraging Hybrid and Multi-Cloud Environments
Distributing AI workloads across hybrid and multi-cloud setups allows organizations to select the most cost-effective and high-performing environment for each task. This flexibility helps avoid vendor lock-in and supports regulatory requirements. Solutions like NexaStack’s hybrid cloud orchestration and XenonStack’s multi-cloud services enable seamless workload migration and dynamic scaling across public and private clouds.
-
Optimize resource allocation by matching workloads to the best-fit environment.
-
Reduce costs by leveraging spot instances or preemptible VMs from different providers.
-
Improve resilience and compliance with distributed deployments.
Using Open-Source and Low-Cost Model Alternatives
Open-source frameworks such as TensorFlow, PyTorch, and Hugging Face Transformers provide robust AI capabilities without licensing fees. Enterprises can also take advantage of pre-trained models and community-driven solutions to accelerate development and reduce operational costs.
- Adopt open-source tools to eliminate vendor licensing fees.
- Use pre-trained models to save on training time and compute resources.
Implementing Intelligent Workload Orchestration
Automated orchestration platforms like Akira AI and NexaStack enable dynamic resource allocation, policy-driven governance, and auto-scaling. By intelligently matching resources to workload demands, these platforms minimize idle capacity and infrastructure waste.
- Automate scaling and resource provisioning based on real-time demand.
- Enforce policies for cost control, security, and compliance.
By combining these strategies, enterprises can create a flexible, efficient AI operating system that supports innovation while keeping infrastructure costs predictable and manageable.
Optimizing AI Workflows Without Sacrificing Performance
Enterprises often worry that cost optimization will come at the expense of AI performance. However, with the right strategies and tools, it’s possible to streamline workflows, reduce infrastructure spend, and still deliver high-quality, scalable AI solutions. The key is to combine intelligent automation, efficient resource management, and advanced model optimization techniques. 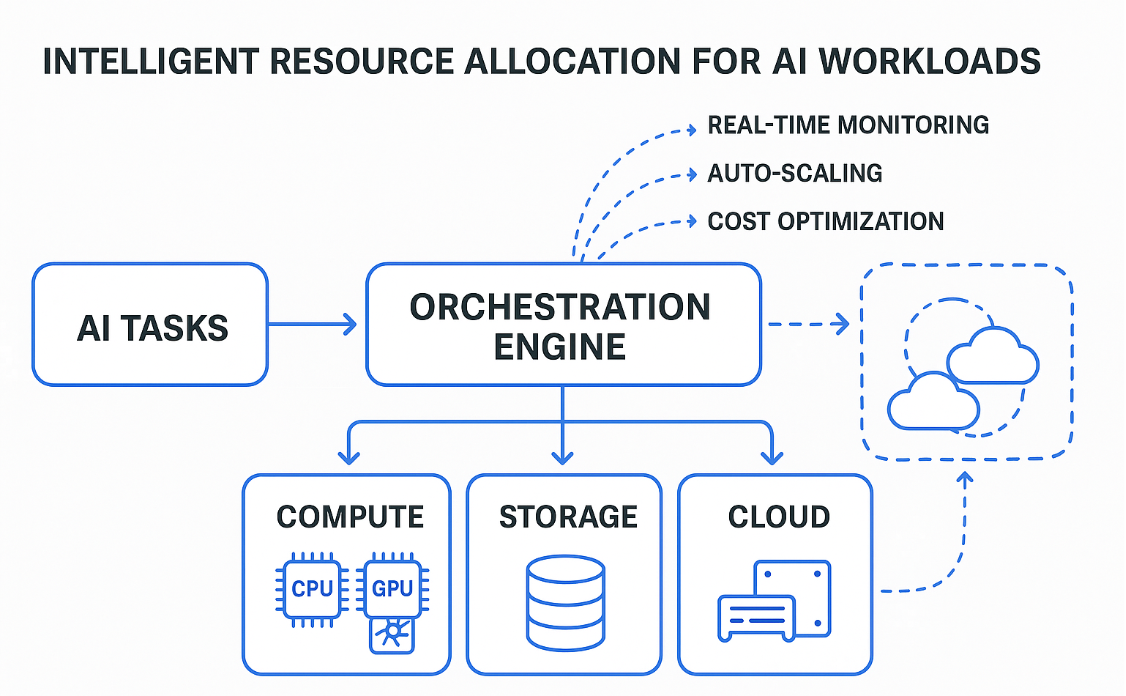
Dynamic Resource Allocation and Auto-Scaling
Modern AI platforms leverage dynamic resource allocation and auto-scaling to ensure that compute and storage resources are provisioned only when needed. By using containerization, virtualisation, and AI-powered scheduling, organisations can maximise hardware utilisation and minimise idle time. Solutions like Kubernetes and AWS Auto Scaling automate this process, adapting to workload changes in real time and helping teams avoid overprovisioning.
-
Automatically scale up for intensive training jobs and scale down during idle periods.
-
Use predictive analytics to match resource supply with demand, reducing waste.
Model Compression, Quantisation, and Pruning Techniques
Optimising AI models themselves is another powerful way to cut costs without degrading results. Techniques such as model compression, quantization, and pruning reduce the size and complexity of models, allowing them to run efficiently on lower-cost hardware or with fewer resources.
-
Model compression: Shrinks model size for faster inference and lower memory usage.
-
Quantisation: Lowers precision to reduce computational needs while maintaining accuracy.
-
Pruning: Removes unnecessary parameters to streamline inference and cut costs.
Major AI leaders like OpenAI and Google use these methods to deploy efficient models at scale.
Serverless AI and On-Demand GPU Usage
Serverless AI platforms and on-demand GPU provisioning let organisations pay only for the resources they use, rather than maintaining expensive, always-on infrastructure. Services like AWS Lambda, Google Cloud Vertex AI Workbench, and Modal support burst workloads and batch jobs with cost-effective, scalable infrastructure.
-
Use spot instances or serverless runtimes for non-critical or batch AI jobs.
-
Leverage tiered storage and data compression to further reduce costs.
By adopting these workflow optimisation strategies, enterprises can maintain high performance, agility, and innovation while keeping AI infrastructure costs firmly under control.

The Role of BYOC (Bring Your Own Cloud) in Cost Efficiency
As enterprises seek greater control over their AI infrastructure spending, Bring Your Own Cloud (BYOC) strategies are gaining momentum. BYOC empowers organisations to deploy AI workloads on their preferred cloud or on-premises environments, rather than being locked into a single vendor’s ecosystem. This flexibility enables teams to optimise infrastructure choices for cost, compliance, and performance, tailoring deployments to business needs and budget constraints.
Gaining Control Over Infrastructure Spending
With BYOC, companies can negotiate better rates, leverage existing cloud credits, and select the most cost-effective regions or services for each workload. This approach also allows for more granular budget management and cost forecasting, as organisations can allocate resources based on real usage patterns and business priorities. According to cloud cost optimisation best practices, evaluating instance types, using spot or reserved instances, and regularly reviewing provider offerings can generate significant long-term savings.
-
Negotiate multi-cloud agreements to secure competitive pricing.
-
Match workloads to the most affordable and performant cloud or on-premises options.
-
Monitor and adjust resource allocation in real time for maximum efficiency.
Enhancing Compliance and Security Without Added Costs
BYOC also supports enhanced compliance and security by allowing organisations to enforce data residency, privacy, and security policies within their chosen environments. This is especially valuable for regulated sectors, where data sovereignty and auditability are critical. With platforms like NexaStack, enterprises can maintain compliance without incurring the extra costs often associated with managed cloud services.
-
Enforce security and compliance policies tailored to industry requirements.
-
Reduce the risk of vendor lock-in and maintain flexibility for future migrations.
Adopting a BYOC approach, supported by intelligent orchestration and continuous cost monitoring, helps enterprises build a cost-efficient, secure, and future-ready AI operating system.
Agentic AI and Automation: Unlocking Cost-Saving Potential
Automation is rapidly becoming a cornerstone of cost-efficient AI operations. As enterprises scale, manual management of AI pipelines and infrastructure can lead to inefficiencies, higher labor costs, and increased risk of human error. By embracing agentic AI and advanced automation, organisations can streamline processes, reduce operational overhead, and achieve sustainable cost savings without sacrificing performance or innovation.
Automating Pipeline Management and Resource Provisioning
Agentic AI platforms automate the orchestration of complex AI workflows, from data ingestion to model deployment. This automation eliminates repetitive manual tasks, accelerates delivery cycles, and ensures that resources are provisioned only when needed. Companies leveraging these solutions often report a 30–60% reduction in infrastructure and operational costs, as highlighted by Azilen’s AI cost optimisation strategies and CAI Stack’s comparative guide.
-
Reduce manual intervention by automating model retraining, validation, and deployment.
-
Dynamically allocate compute and storage resources based on real-time demand, minimising idle capacity.
Real-Time Monitoring and Self-Healing Infrastructure
Modern AI operating systems integrate real-time monitoring and self-healing capabilities, using AI-driven insights to detect anomalies, predict failures, and trigger automated remediation. This proactive approach reduces downtime and troubleshooting costs and supports continuous optimisation, as seen in ISG’s AI-powered cost optimisation practices.
-
Enable continuous visibility into resource utilisation, performance, and cost trends.
-
Implement self-healing workflows that automatically resolve common infrastructure issues, freeing up IT teams for higher-value work.
By adopting agentic AI and automation, enterprises can unlock new efficiency and cost control levels, building a resilient AI operating system that scales with business needs and market demands.

Case Study: Cutting Costs While Driving AI Innovation
A global healthcare provider set out to modernise its AI infrastructure to support advanced diagnostics and predictive analytics, but faced mounting costs from cloud overuse, idle resources, and manual pipeline management. By adopting a hybrid cloud strategy with NexaStack and integrating intelligent workload orchestration from Akira AI, the organization could dynamically allocate compute resources, automate scaling, and enforce cost-control policies across cloud and on-premises environments.
Healthcare: AI-Driven Hybrid Cloud Optimisation
A multinational healthcare organisation implemented AI-based tools to manage its hybrid cloud infrastructure. By deploying predictive resource allocation and intelligent workload distribution, the company achieved:
-
25% reduction in cloud-related operational costs
-
30% improvement in workload efficiency
-
40% reduction in downtime
These results were made possible through automation, dynamic scaling, and proactive performance monitoring, demonstrating how modern orchestration can deliver both cost savings and operational resilience.
Manufacturing: Predictive Maintenance and Efficiency
An automotive manufacturer adopted an AI-powered predictive maintenance system to monitor equipment and optimise production schedules. The impact included:
-
50% reduction in unplanned downtime
-
20% increase in production output
-
$2 million in annual savings from reduced maintenance costs and improved efficiency

Conclusion: Innovate Smarter, Not Costlier
Building a cost-efficient AI operating system is essential for sustainable enterprise innovation. Organisations can control infrastructure spending without sacrificing performance or agility by combining hybrid and multi-cloud strategies, open-source tools, and intelligent workload orchestration. Real-world results show that automation, dynamic scaling, and BYOC approaches cut costs, accelerate AI deployment, and improve resilience. The future of enterprise AI belongs to those who innovate smarter, optimising every layer for both ROI and rapid growth.