As digital transformation accelerates, organizations are adopting Optical Character Recognition (OCR) to extract structured data from printed and handwritten sources efficiently. OCR is at the core of intelligent document processing systems, automating invoice processing and enabling real-time ID verification. However, building and deploying an accurate and scalable OCR model can be challenging without the right tools and infrastructure.
This blog explores how to effectively deploy an OCR solution using EasyOCR, an open-source, deep learning-based OCR library, and NexaStack, a modern platform that simplifies MLOps and cloud-native deployments. EasyOCR supports multiple languages and scripts, making it a versatile choice for organisations with diverse document formats. On the other hand, NexaStack offers a unified environment for managing infrastructure, pipelines, and model lifecycle, ensuring smooth and consistent operations from development to production.
We’ll guide you through a structured deployment approach, from assessing business impact and implementation planning to integration, performance tuning, and ROI measurement. With a well-defined strategy, you can streamline document workflows, reduce manual effort, and improve data accuracy and processing speed.
Whether you're a developer, data engineer, or business leader, this blog will help you understand the practical steps and best practices in deploying large-scale OCR models. You’ll also gain insights into governance, monitoring, and optimization to maintain high performance and compliance over time.
By combining the simplicity of EasyOCR with the robustness of NexaStack, you can build a future-ready OCR pipeline that delivers real value across industries like finance, logistics, healthcare, and beyond. Let’s dive into the deployment journey and discover how to quickly and confidently bring OCR into real-world production.
Key Insights
Deploying an OCR model with EasyOCR and NexaStack involves streamlined integration, real-time monitoring, and continuous optimization for reliable text extraction.
Model Integration
Seamless deployment into existing workflows using NexaStack tools.
Input Validation
Verifies image and text inputs match expected formats.
Performance Tracking
Monitors accuracy, speed, and output quality in production.
Iterative Updates
Improves model based on real-world feedback and data.
Evaluating the Impact of OCR Deployment
Before implementing an OCR model, it is essential to understand its implications for your organization. OCR systems build a bridge from paper-based processes to digitised systems by converting scanned documents, images, and handwritten notes into machine-readable text. This value is heightened in verticals such as healthcare, finance, logistics, and legal services, where burdensome paper-based and/or unstructured data inhibit operational efficiencies.
The main benefits of OCR implementation are:
-
Process Digitisation: Automated data entry for invoices, contracts, or forms greatly minimises human error and processing time; for example, a logistics company could extract shipping details from labels in a few moments instead of minutes.
-
Improved Data Utilization: Digital text is searchable and analyzable for insightful decision-making; for example, a financial institution may use OCR to extract data from loan applications for risk assessment.
-
Efficiency in Operations: A Big advantage to eliminate the repeated tasks in which employees are engaged and allow them to focus on higher value engagements, such as customers and strategic vital decisions.
The impact will vary depending on the use case. An impact assessment should assess:
-
Volume of documents processed daily.
-
Existing error rates in your manual workflows.
-
Time consumed manually entering and validating data.
-
Potential cost savings and productivity gains.
For example, a retailer with 1,000 daily invoices, each with a 5% error rate, could save hours of rework and enhance relationships with their suppliers by implementing OCR, or “optical character recognition.” In this case, the retailer would want to gain the value of OCR as quickly and simply as possible. In this case, EasyOCR is lightweight and open-source, and NexaStack is a scalable platform deployment that can swiftly realise these benefits efficiently and cost-effectively.

Step-by-Step Implementation Plan
To deploy an OCR model successfully, it's critical to have a distinct plan for ensuring success. Below is the sequence of steps to follow using EasyOCR and NexaStack:
-
Objectives: Select specific digitisation processes, such as invoice processing and customer onboarding. Set measurable improvements with stated goals, such as "30% less processing time" and "50% fewer errors".
-
Tools: EasyOCR is a good choice due to its ease of use, ability to run on minimal hardware, and support for more than a hundred languages. NexaStack will complement EasyOCR by providing a good deployment environment to support scaling and monitoring.
-
Data Collection: Collect documents to simulate the processes selected from the first two steps. PDFS or scanned images are candidates for documents. Preprocessing imaging, such as cropping, denoising, or highlighting contrast in the image, may be needed to achieve better accuracy.
Configure it for laanguage of your choice:
import easyocrreader = easyocr.Reader(['en'])
result = reader.readtext('invoice.jpg')
The extracted text can then be structured into usable formats such as JSON.
-
Pilot: A pilot can then be run with a small dataset (sample prior) to validate accuracy and iteratively "stress test" Or find when errors such as handwriting and low-resolution scans begin to happen.
-
Deploy: With NexaStack, deploy the OCR running as a microservice. NexaStack has a container environment for running software containers, which provides agility with updates and easier scaling.
Architecture and Integration Blueprint
To achieve maximum value, OCR services must integrate seamlessly into existing systems and workflows. A proper integration framework allows digitized data to flow into business processes easily.
-
Connect To Core Systems: We can connect outputs from OCR technology into software you are currently using such as a CRM, ERP, or document management system. For example, a retailer can use extracted invoice data and feed it directly into their accounting software eliminating all manual reconciliation.
-
Automate Your Workflows: Consider designing workflows where OCR technology triggers further downstream actions such as updating inventory after scanning delivery notes or flagging down discrepancies in the contract to be reviewed by a user.
-
Enable User Access: Create an easy-to-use interface for employees to upload documents and view the output (e.g. web or mobile apps), providing access without the requirement of a technical background.
-
Ensure Flexibility: Finally, develop or choose a platform, such as NexaStack, which will support integration with different core systems while offering the ability to future proof the platform.
Optimizing Model Performance at Scale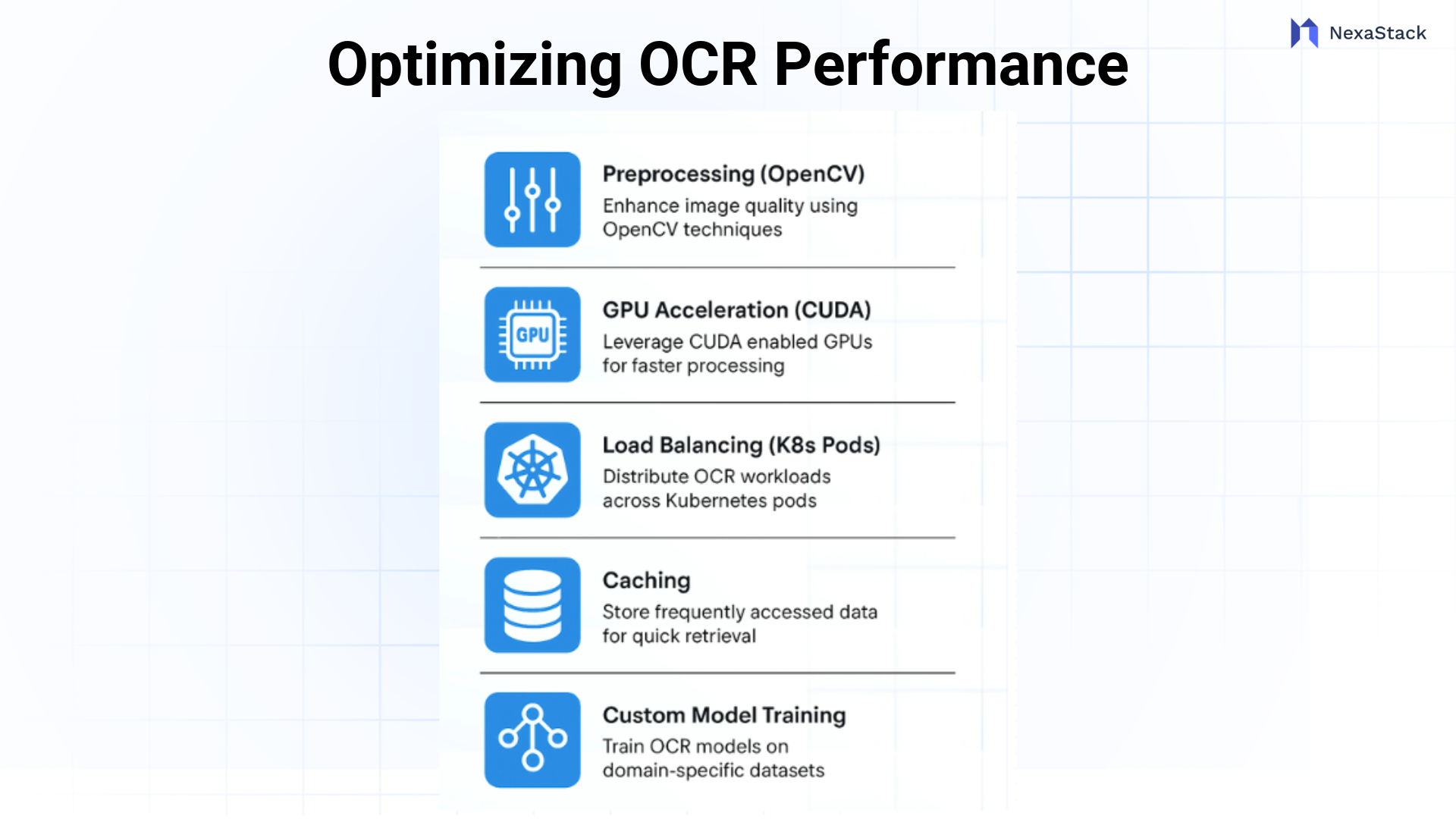
To guarantee the OCR service performs reliably at the scale we need, optimization is required. EasyOCR and NexaStack provide several levers for enhancing efficiency during OCR processing:
- Pre-processing: Use OpenCV to enhance image quality. For example:
import cv2
image = cv2.imread('document.jpg', 0) # Grayscale
image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY cv2.THRESH_OTSU)[1]
This itself will often increase EasyOCR’s accuracy on noisy scans.
2. Hardware Acceleration: EasyOCR can utilize GPU acceleration through CUDA. When utilising NexaStack, deploy the service to GPU-enabled nodes to rapidly process large batch documents.
-
Load balancing: NexaStack’s orchestration (Kubernetes or similar) can orchestrate load among multiple instances to maintain low latency during heavy usage.
-
Caching: Consider caching document templates frequently processed in memory so that OCR does not need to run on the same information repeatedly.
-
Fine-tuning—If accuracy suffers with specific fonts or layouts, the underlying models (for example, Tesseract) used by EasyOCR can be further trained with custom datasets. NexaStack’s ML tools will alleviate most of the complexity associated with that process.
For example, a bank could have 10,000 checks to process in a day. With GPU acceleration on top of load balancing, it is conceivable to process the checks in less than an hour vs literally days for manual entry.
Best Practices for Governance and Compliance
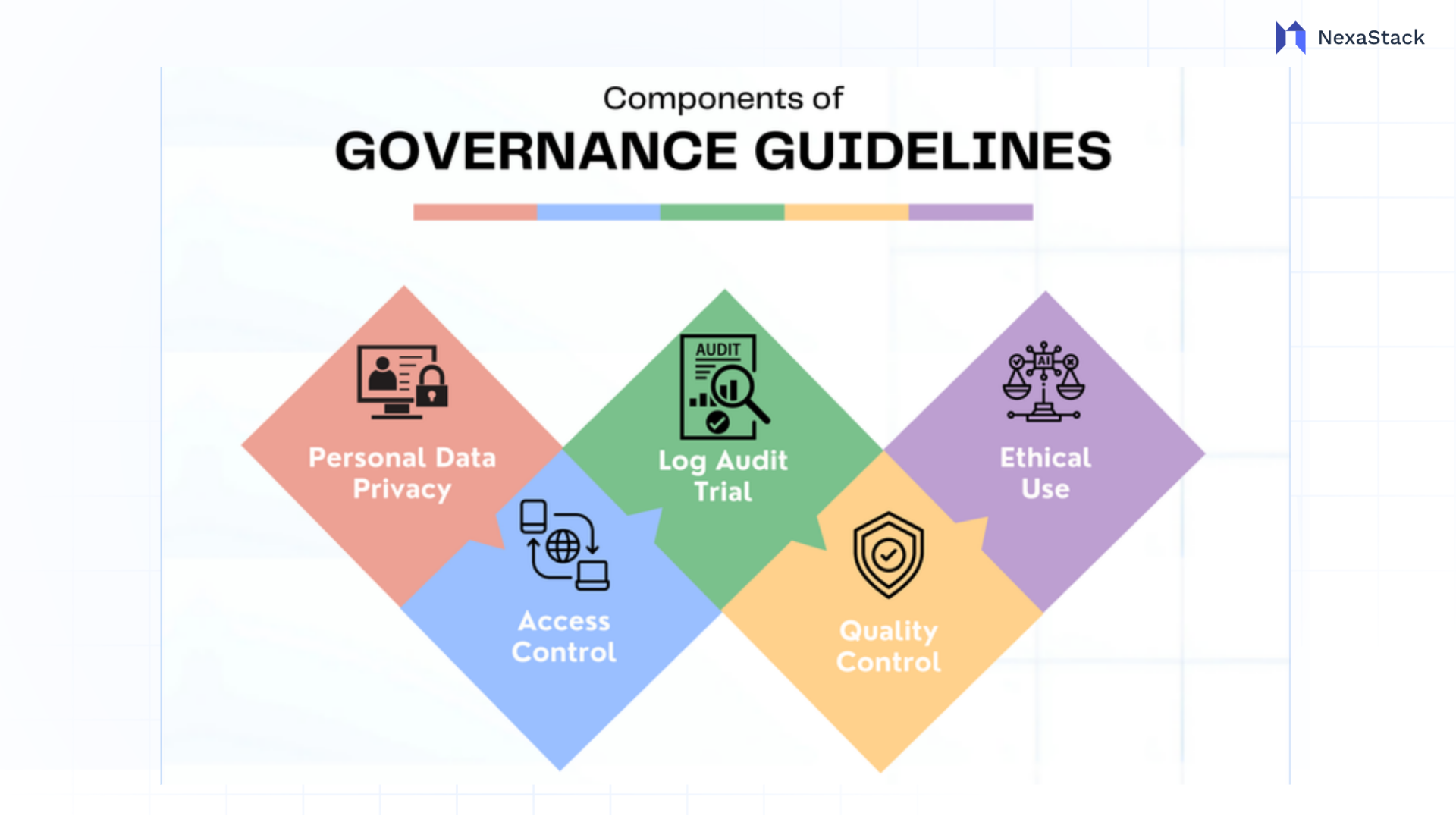 Fig. 2 Governance Guidelines
Fig. 2 Governance GuidelinesGovernance is necessary to ensure compliance, security and ethical use are prioritised when deploying OCR services.
-
Personal Data Privacy: Typically, OCR provision handles sensitive data (e.g., names, financial data, etc.). If your organization uses NexaStack’s encryption services, you can keep data encrypted at rest or in transit.
-
Access Control: Use NexaStack’s authentication modules (e.g., OAuth) to grant authorized users access only to the OCR API.
-
Log Audit Trail: Maintain a log of all OCR requests and outputs using NexaStack’s monitoring systems to ensure compliance (if necessary) and troubleshoot any issues.
-
Quality Control: Routinely review OCR outputs for accuracy, particularly when the how and reasons being applied are more serious. Ensure you establish the human-in-the-loop processes for validation for critical errors.
-
Ethical Use: Do not use OCR to extract data without consent or for presumptive discriminatory purposes. Establish explicit guidelines for the reasonable use of OCR technology.
For example, a healthcare provider could adopt the governance and guidelines suggested for preparing OCR patient records in compliance with laws or regulations, thus improving care and record delivery.

Measuring ROI and Operational Benefits
To validate the investment in the deployment of OCR, you can calculate return on investment (ROI) with both quantitative and qualitative measures:
-
Cost Savings: You would quantify costs saved in labor. If you pay $50,000 for employees to enter data manually, and OCR helps save 80% of that effort, you save $40,000.
-
Time Savings: You would measure the time saved on a task. If processing invoices takes 5 minutes and OCR reduces it to 30 seconds, this is quite the productivity boost.
-
Error Reduction: Most organizations consider the cost of errors (rework, penalty, cause of losses) both before and after OCR deployment—you would quantify how much error reduction saves before deploying OCR, then observe how much you save after starting to use OCR. If you can reduce the error rate by 50%, you will save thousands per month when higher volumes are needed.
-
Revenue Impact: You would measure how much faster processing rates increase revenue. For example, if customers are onboarded hastily, it results in a 10% increase in sales by processing customers in half the time.
-
Benefits: Other benefits to consider include employee satisfaction because there is less tedious work with a product like OCR and improved customer experience due to the faster processing time. Both of these benefits are value-added for the long term.
To calculate ROI:
ROI (%) = [(Benefits - Costs) / Costs] × 100
 Summary and Key Takeaways
Summary and Key Takeaways
Implementing an OCR model with EasyOCR and NexaStack is an impactful way to digitise processes, increase data use, and support efficiency. Through impact assessments, leverage structured implementation, establishment of systemic ways of integrating with existing systems, performance management, governance adherence and ROI measurement, every organisation can unlock the power of OCR. Whether it is a small firm streamlining invoices or a large corporation preparing to digitise archives, OCR has real, measurable results, with lowered complexity. To get started, go small, iterate quickly and scale smart. OCR is your passport to a new and more efficient life.


























